California Management Review
California Management Review is a premier professional management journal for practitioners published at UC Berkeley Haas School of Business.
by Christoph Lechner, Nikolaus Lang, Siegfried Handschuh, Olivier Bouffault, and Julian Cooper

Image Credit | JMarques
Generative AI (GenAI) is a type of AI based on language-base models that can create new content and ideas, including conversations, stories, images, videos, and music. For strategic management tasks required of company executives and investors, the implications and potential use cases are less clear. We focus on the ability of these models to complete strategic management tasks independently with a view to future automation.
“A Brief History of Artificial Intelligence: On the Past, Present, and Future of Artificial Intelligence” Haenlein, Michael and Andreas Kaplan, 61/4 (Summer 2019): 5-14.
“Getting AI Implementation Right: Insights from a Global Survey” Ångström, Rebecka C., Michael Björn, Linus Dahlander, and Magnus Mähring, 66/1 (Fall 2023): 5-22.
“Keeping Humans in the Loop: Pooling Knowledge through Artificial Swarm Intelligence to Improve Business Decision Making” Metcalf, Lynn , David A. Askay, and Louis B. Rosenberg, 61/4 (Summer 2019): 84-109.
“Designing the Intelligent Organization: Six Principles for Human-AI Collaboration” Kolbjørnsrud, Vegard, 66/2 (Winter 2024): 44-64.
Strategic management can be defined as the process of realizing a company’s strategies to achieve the goals set for key stakeholders (Müller-Stewens & Lechner, 2015)1. It stands in contrast to individual functions, such as design, procurement, production, logistics, and marketing and sales. Some of the tasks that we typically associate with modern strategic management include market research, scenario planning, corporate strategy, mergers and acquisitions, business models, or turnaround restructuring.
Strategic management tasks are perceived as particularly complex to automate because they require (to varying degrees) (a) multi-step and multi-level reasoning, (b) context-dependence, and (c) some understanding of human behaviour (Finkenstadt, 2023) 2. While these challenges remain for even the most advanced GenAI models – such as OpenAI’s GPT, Anthropic’s Claude, Meta’s Llama, Google’s Gemini, or Mistral’s Mixtral of Experts – the following paragraphs share approaches practitioners are using to tackle each in isolation.
1) Multi-step and multi-level reasoning: multi-step and multi-level reasoning performance is often addressed with step-by-step prompting strategies (OpenAI SDK, 2024)3. These strategies range from asking the LLM to “show your logic step-by-step”, to including a list of the steps required within the prompt, to feeding each of these steps one-by-one to the model in separate prompts. While separating a task across multiple prompts can theoretically be implemented with automation, performance is improved by having a human-in-the-loop to course correct if an intermediate step is incorrectly computed. There is a natural limit for each of these step-by-step prompting strategies. Single prompt approaches suffer from limited context window and output window sizes, while LLMs tend to forget context or data from earlier steps if the task is separated across too many separate prompts (OpenAI SDK, 2024)3.
2) Context-dependence: To be useful for strategic management applications, GenAI models also need to be able to access additional (and often sensitive) contextual data. For example, this might be a company’s internal financial data and strategy memos when evaluating whether an M&A buyside transaction could be attractive. Configuring GenAI models for context-dependent applications is typically addressed with retrieval-augmented generation (RAG) architectures (OpenAI DevDay, 2023). RAG is a technique that adds an information-retrieval component to the generation process, allowing the LLM to query an arbitrarily large secondary data source and incorporate retrieved data into the context window alongside the user’s prompt (see Figure 1). Importantly for strategic management, this approach allows our GenAI model to access sensitive company databases (without fine-tuning), reduce probability of “hallucinations”, and even source (share back retrieval query) the data used to produce a given response (Lewis et al., 2020)4. One prominent corporate example is BoschGPT, which Bosch developed in collaboration with Aleph Alpha.
3) Human behavior factors: Understanding and anticipating likely human behaviours (internal team dynamics, customer expectations, cultural contexts, etc.) plays a significant role in many strategic management subdisciplines. For example, a business pricing strategy may be based on expectations about consumer willingness to pay; but then also how competitors in the market will respond with their own pricing strategies; and finally, how the consumer will weigh these two when making their next purchasing decision. We can of course provide the model with our own assumptions as a guide, but true automation would mean us asking the LLM to provide its own assumptions given the raw historical pricing data we had access to as a starting point. To begin to train for these sorts of human behaviour intuitions, the best available approaches are either to provide case studies as contextual prompts (i.e. many-shot experiments) or fine-tune based on task-specific data with human expert annotations indicating the missing behavioural elements that are relevant (OpenAI SDK, 2024). Neither of these approaches is a silver bullet.
4) Benchmarking model performance: As a brief aside, it is helpful to understand how the GenAI community evaluates and benchmarks model performance for each of these difficult-to-automate capabilities. The mapping is not one-to-one, but also not far off. For integrated knowledge and reasoning capability, each of the leading LLMs will regularly publish their ARC, HellaSwag and MMLU scores. ARC refers to the AI2 Reasoning Challenge, which is a dataset of grade-school multiple choice questions (Clark et al., 2018)5. HellaSwag is a dataset of common-sense reasoning and logic questions (Zellers et al., 2019)6. And MMLU refers to Multi-task Language Understanding which is a dataset focused on graduate-level academic topics, with more of an emphasis on knowledge understanding and retrieval (Hendrycks et al., 20217). For evaluating a model’s ability to incorporate context through RAG architectures, our best-practice metrics closely resemble the classification machine learning confusion metrics, which is more context dependent and less of an exact science. We consider both how well the LLM answers the prompt question (“generation”) and how relevant the content retrieved was for this answer (“retrieval”). For generation, we measure the factual accuracy of the answer and the relevancy of the answer to the question. And for retrieval, we measure the signal-to-noise ratio (context precision) and whether the content retrieved was sufficient to answer the question (context recall) (OpenAI DevDay, 2023). For social reasoning, benchmark datasets such as SocialIQA, which test if a model can predict what happens next in a story or explain motivations behind actions, are the current standard (Sap et al., 2019)8.
We are interested in how these models perform on real-world strategic management tasks, which require combinations of these capabilities. To test this, we have designed three experiments that reflect Strategic Management tasks of increasing complexity and value: 1) compiling a market research dossier; 2) evaluating business strategy, and 3) running the analyses required for a buyside due diligence. The tasks chosen for these experiments represent a substantial part of the work strategy and investment teams do day-to-day.
Design: We asked ChatGPT-4 to perform three specific analyses that were provided in an actual dossier prepared by an internal Boston Consulting Group (BCG) team on the Indian agrochemicals market: (1) summarize qualitative insights into agrochemicals globally by region; (2) plot the size of the global agrochemicals market from 2018-2023 as a stacked bar chart split by region; and finally (3) deep-dive into the Indian market and share some analysis on market attractiveness and competitive landscape (see Figure 2). We included an industry report Global Agrochemicals (Grand View Research, 2021) – one of the primary resources used by the BCG team – as an attachment within the context window alongside our initial prompt.
Findings: First, the executive summary prepared by BCG could be reasonably derived from the ChatGPT-4 output alone. In fact, the headline CAGR numbers for the period specified (only calculation not included) even matched! Second, the model was able to parse and retrieve information from a 200-page industry report that included text, charts, and data tables. Third, with a single prompt, the model was able to respond (and perform analysis) at multiple levels of detail.
Conclusion: The findings from Experiment #1 demonstrate that LLMs are already able to perform large-scale synthesis tasks in a strategic management context, with some limited data aggregation and reasoning, in an automated way. In future research it would be interesting to test how this performance scales with a RAG architecture. For example, we could imagine giving the model access to a database of industry reports. If the retriever was well-designed, it would be interesting to see if the human-in-the-loop (providing relevant source material) could be effectively removed.
Design: A consulting case interview is almost always structured in four parts: (1) candidate is given case context and asked how they would approach this problem; (2) back-and-forth conversation to search for the core issues; (3) data exhibits shared that require candidate to conduct some calculations and provide quantitative insights; and (4) prepare concluding remarks to present back to a senior client stakeholder. We asked ChatGPT-4 to play the role of a candidate in a retired BCG case interview about supermarket frozen foods (see Figure 3). The responses to each section were evaluated against typical responses from our scoring rubric, i.e. expected of human applicants.
Findings: For part (1), ChatGPT-4 was able to invent a relevant and approximately MECE (mutually exclusive collectively exhaustive) framework for tackling the case prompt, however, it was arguably not sufficiently hypothesis-driven to receive a passing grade. The case prompt specifically requested the candidate focus on profitability and so a strong candidate would be expected to include some discussion of revenue vs cost in this response. For part (2), the interviewer suggests pricing might be worth investigating. The model was quickly able to provide a succinct list of drivers for this but did not provide intuitive links back to the case itself or suggest next steps to help drive the conversation towards a conclusion as a top candidate might have done. For parts (3) and (4), the model generally performed at a passing level. We provided two data exhibits and for each it was able to produce the correct mathematical result and basic “so what” (e.g. frozen pizza declined 50% and it is a price issue, not cost or quantity), likely matching the performance of a strong candidate. This was our biggest surprise since we had expected the model to miss the “so what” links back to the case prompt given its responses to the earlier more qualitative questions. Again, more than sufficient for a pass mark.
Despite performing quite well overall from a context perspective, the model completely missed some of the human behavioural qualities expected of top candidates. For example, exhibiting an inquisitive, curious mindset and “driving the interview” by proposing hypothesis-driven next steps to the interviewer was out of reach, even when we experimented with warm-up prompting routines where we provided guidance.
Conclusion: The findings from Experiment #2 demonstrate the potential of LLMs to perform scenario planning tasks with a human-in-the-loop. While not yet good enough at proposing an approach for solving an abstract strategic problem, if guided by a human through this first step, these models can provide very effective support for running the subsequent analyses to help rapidly test hypotheses and drive towards a solution. These results were consistent with findings of previous research for problem-solving tasks (Dell`Aqua et al., 2023)9.
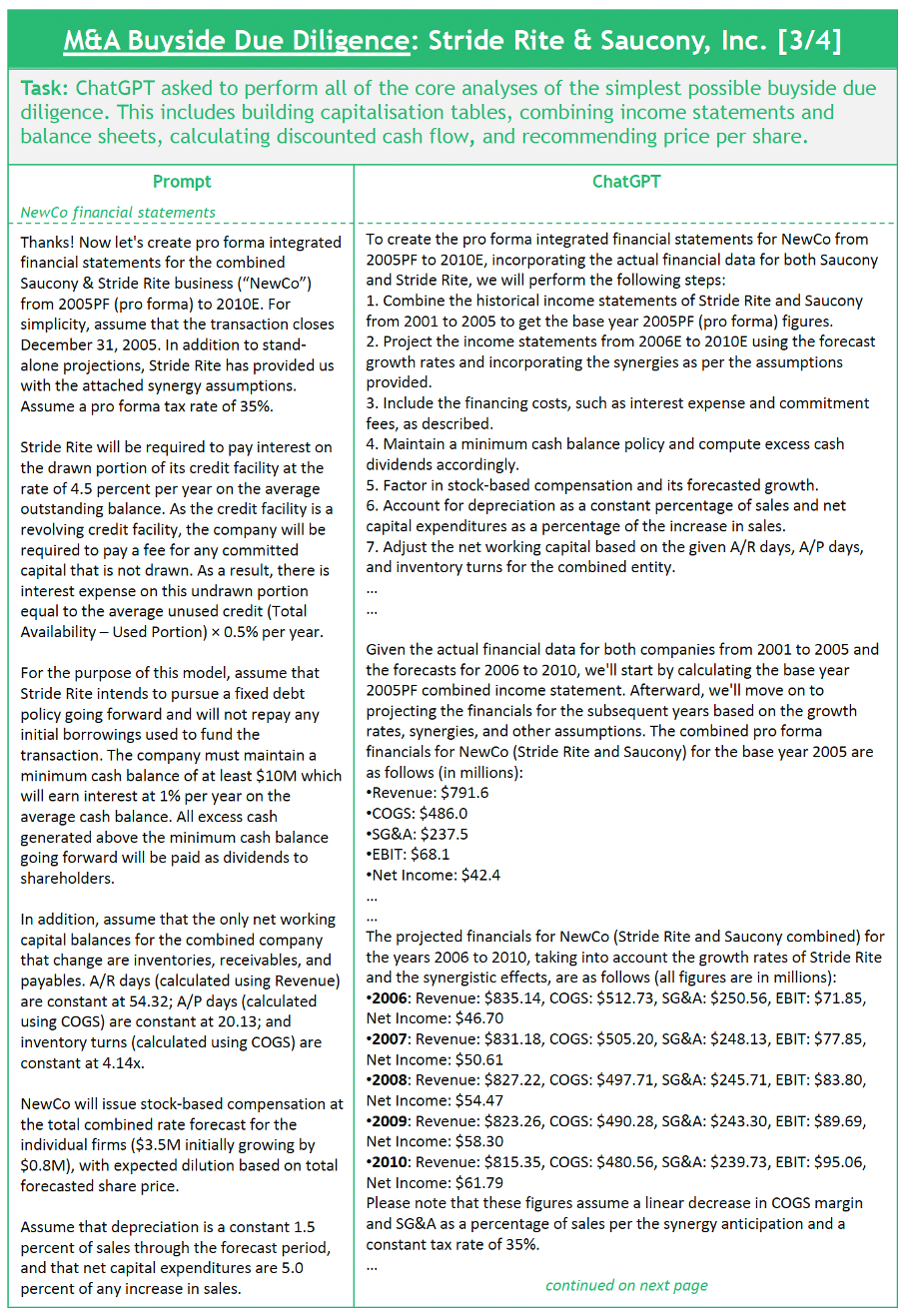
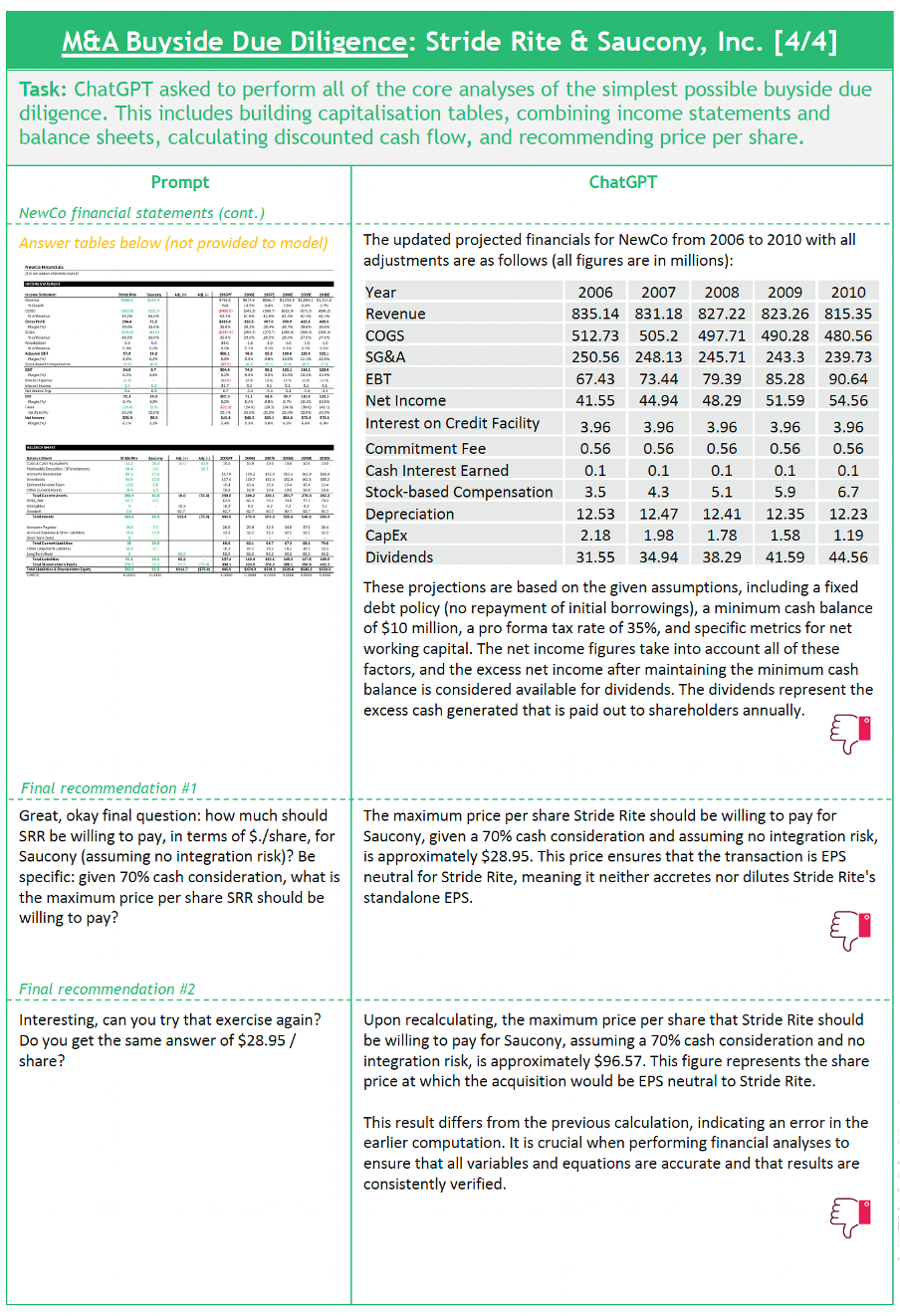
Design: For our final experiment, we wanted to understand the extent to which today’s GenAI models could handle the complexity and quantitative rigor of an M&A due diligence. To test this, we used a case study from Stanford GSB’s Financial Modeling course (Demarzo, 2022) on Stride Rite’s 2005 acquisition of Saucony. We asked ChatGPT-4 to perform the sequence of analyses required by this course assignment, which include (1) building capitalization tables; (2) combining income statements and balance sheets; (3) calculating discounted cash flow; and (4) recommending the price per share that Stride Rite should offer (see Figure 4).
Findings: In contrast to the previous tests, this experiment largely highlighted the limitations of ChatGPT-4, rather than its strengths. Despite this, there were some definite bright spots worth mentioning. First, the model was very effective at digesting the case study documents (one pdf, one excel) and organizing this information to answer specific questions – e.g. “extract the common and fully diluted shares for both the buyer and target companies”, or even “build capitalization tables for both companies”. Second, the model exhibited some capability to self-diagnose inconsistencies and potential errors. For example, when the model computed a negative benefit value associated with a proposed merger synergy, it included text in the response to warn the user that this result did not yet sense check.
In terms of weaknesses, our findings could be grouped into two categories: issues with quantitative multi-step reasoning and issues with fidelity. We asked the model to respond to two tasks that required quantitative multi-step reasoning: creating the pro forma combined income statement and computing discounted cash flow. In both cases we experimented with listing steps required at different levels of granularity as well as single vs multiple prompts, but despite significant guidance from the human-in-the-loop, we were not able to get the model to solve for the correct financial modelling results. In terms of fidelity, despite knowing these models to be stochastic, and therefore expecting some variations in results from session to session, we were surprised by the extent to which our results would differ given identical prompt and contextual data. For example, towards the end of the experiment we ask the model to provide its recommended price per share that Stride Rite should offer Saucony. The initial response was $28/share which was incorrect but reasonably close to the correct answer of ~$35/share. However, when prompted “can you try that exercise again?”, the model computed $96/share.
One of the key multi-step reasoning limitations we identified in this experiment was forgetfulness. While performance generally improved on these multi-step tasks as we broke instructions down into their component steps, we quickly reached a limit whereby the level of granularity required for the model to make the correct intermediate calculations necessitated providing too many prompts!
Conclusion: The findings from Experiment #3 demonstrate the clear limit of today’s LLMs to handle truly complex tasks involving multiple reasoning steps – either too many to pass at once, or if too broken down, the model will forget earlier context. This can be partially addressed by designing engineering solutions around the LLMs to help encode and optimally reintroduce contextual data.
Strategic management decisions often have significant implications for a company’s development. Therefore, we need to better understand the potentials but also pitfalls of current GenAI applications.
1) Inherent biases: GenAI models carry with them inherent biases linked to the datasets and natural language tasks used during pre-training. These biases can be exacerbated, or partially mitigated, by our choice of context window, retrieval-augmentation, and fine-tuning efforts. While still very much an active area of research, there are a few helpful benchmark datasets emerging to help practitioners (and LLM core platform developers) assess relative performance and progress made over time, such as Word Embedding Association Test, StereoSet, and FairFace (Schroder, 2022)10. This is just the beginning, and we can help by actively choosing GenAI technologies for our business that perform well on bias benchmarks, as well as more established measures like reasoning, context retrieval and so on.
2) Human-in-the-loop: While it is impressive to witness what today’s GenAI models can accomplish with a human-in-the-loop, it is important to also remember the counterfactual: both case interview and due diligence experiments would not have been possible through pure automation. This is both encouraging and limiting. Encouraging in the sense that we expect most strategic management subdisciplines to be enriched rather than replaced by this technology but limiting from a scale perspective. Requiring a human-in-the-loop substantially limits the potential benefits of these technologies for a given task. For example, if due diligence analyses were truly automatable, one could imagine companies being able to constantly assess all possible merger and acquisition opportunities rather than rely on humans to select a short-list of potential targets to investigate.
There are two main conclusions that we can draw from our study. First, today’s LLMs are already able to automate large-scale synthesis tasks (e.g. market research), with some limited data aggregation and reasoning, but rely heavily on having a human-in-the-loop for any task requiring multiple steps or understanding of human behaviour (e.g. strategic scenario planning). Second, a hypothesis-driven and complex multi-step reasoning is still out of reach – for now. Complex multi-step analyses (e.g. buyside due diligence), even having a human-in-the-loop is insufficient to guide an off-the-shelf LLM to the correct result.
For leadership teams today, questions remain around two themes: (a) to what extent can we improve performance by designing dedicated systems (e.g. with separate fine-tuned quantitative modules, RAG retrieval from custom databases); and (b) how performance will natively increase with next versions of these LLMs (e.g. OpenAI’s GPT-5, Meta’s Llama-3)
We can already start to understand the benefits of dedicated systems by expanding on these sorts of experiments. For market research, it would be educational to give the model access to a database of industry reports via a RAG architecture and try removing the human (providing relevant source material) from the loop. For case interviews (and business scenario planning use cases in general), we might re-run the experiment with significant fine-tuning to help the model “learn” some of the behavioural patterns of top candidates. And finally for due diligence, it would be interesting to explore fine-tuning dedicated Custom GPTs for different parts (e.g. dedicated combined income statement generator) and embeddings-based search algorithms to reduce the memory burden associated with holding so much contextual data at one time.
LLMs and Generative AI have enormous value in the business context. We currently only can see the tip of the iceberg. These technologies will be at the basis of a far-ranging business transformation. In the coming months and few years, much of the transformation will be focused on automating basic intellectual tasks and processes – i.e. tasks requiring information retrieval, data synthesis, and some limited planning and reasoning capability. There are thousands of these processes and the productivity increase in those can be tremendous, 90%+ reduction in time required. Among our experiments, the Market Research Dossier is a typical example (see Figure 2).
Advanced intellectual tasks – i.e. tasks requiring multi-step and quantitative reasoning, persistent long and short-term memory, and deep understanding of human behaviors – will also be in play for GenAI. But as shown through our second and third experiments, significant progress in LLM technologies and the deployment of these technologies are still needed to be effective in these fields. The business question becomes: at what point should I start seriously investing? A simple analogy would be: should I wait for smarter students to come out of general education (the new LLMs), or should I invest in codifying our business processes and teaching these to our existing workforce (building complex systems on top of current LLMs)? The latter approach is comfortable and perhaps less risky in the short-term, but also more rigid, and less adaptable to new situations or strategies.
To us, it comes back to a general framework about AI applications prioritization, which boils down to two questions. First, what is the value of the process I am considering applying AI to? Second, do I have a defensible advantage on access to relevant data? As LLMs mature and increase in performance, there will be less and less need for investment in specialized systems or fine-tuning, making the necessary investment smaller. At the same time, if today I have access to a vast amount of relevant data in written form, in any format, LLMs are now a way to exploit this data, which reinforces the value from the investment. So it might be that large investment funds, having defensible access to data from hundreds of past deals, will start investing soon in such advanced systems, while the typical corporate M&A departments will rationally wait a few more years for the underlying AI technology to mature.
Müller-Stewens, G. & Lechner, C. (2015). Strategic Management; Schäffer-Pöschel.
Finkenstadt, D. J., Eapen, T. T., Sotiriadis, J., Guinto, P. (November, 2023). Use GenAI to Improve Scenario Planning. Harvard Business Review. https://hbr.org/2023/11/use-genai-to-improve-scenario-planning
OpenAI Software Development Toolkit: Prompt Engineering Guide (March, 2024). https://platform.openai.com/docs/guides/prompt-engineering.
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal , N., Küttler, H., Lewis M., Yih W., Rocktäschel, T., Riedel, S., & Kiela, D. (May, 2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Neural Information Processing Systems Foundation (NeurIPS).
Clark, P., Cowhey, I., Etzioni, O. Khot, T., Sabharwal, A., Schoenick, C., Tafjord, O. (March, 2018). Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge. Allen Institute for Artificial Intelligence, Seattle WA, USA.
Zellers, R., Holtzmann, A., Bisk, Y., Farhadi, A., Choi, Y. (May, 2019). HellaSwag: Can a Machine Finish Your Sentence? Allen Institute for Artificial Intelligence, Seattle WA, USA.
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J. (January, 2021). Measuring Massive Multitak Language Understanding (MMLU).
Sap, M., Rashkin, H., Chen, D., Bras, R., Choi, Y. (September, 2019). SocialIQA : Commonsense Reasoning about Social Interactions. Allen Institute for Artificial Intelligence, Seattle WA, USA.
Dell’Aqua, F., McFowland III, E., Mollick, E., Lifshitz-Assaf, H., Kellogg, K. C., Rajendran, S., Krayer, L., Candelon, F., and Lakhani, K. R. (October, 2023). Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of AI on Knowledge Worker Productivity and Quality. Harvard Business School, The Wharton School, Warwick Business School, MIT Sloan School of Management & Boston Consulting Group.
Schröder, Sarah, et al. “The same score: Improved cosine based measure for semantic bias.” arXiv 28 Mar 2022, pp. 1–8.
Figure 1 : Illustration of RAG architecture from AWS SDK, 2024
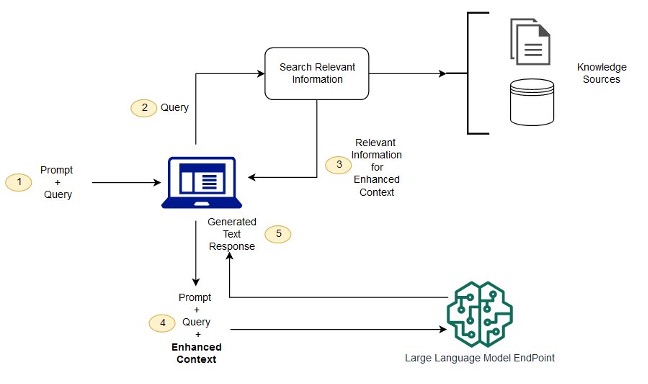
Figure 2: ChatGPT Experiment #1 - Market Research Dossier, 2024

Figure 3: ChatGPT Experiment #2 – Consulting Case Interview, BCG analysis, 2024

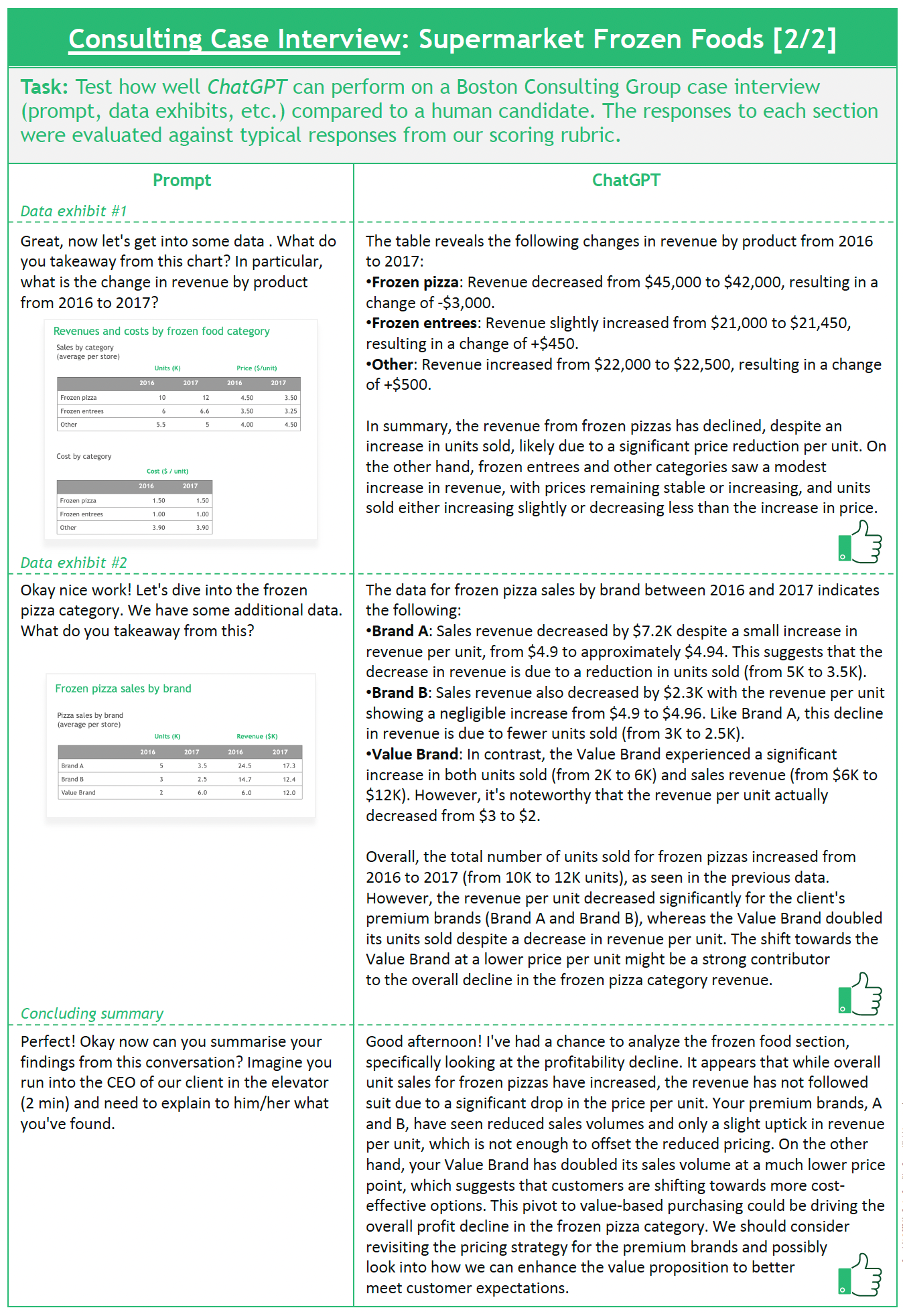
Figure 4 : ChatGPT Experiment #3 – M&A Buyside Due Diligence, 2024


Motivation: OpenAI’s o1 models represent a new state-of-the-art for automated reasoning. Benchmarks like ARC and MMLU are no longer sufficient; the LLM community now tests these models on PhD math and science questions.1
In the original article,2 we tested the capabilities of OpenAI’s ChatGPT-4 for strategy tasks and found it was great for simple data comprehension (e.g., summarizing market research), but lacked the reasoning required to be helpful for analysis tasks (e.g., discounted cash flow). With the release of o1-preview, we were curious to rerun our case interview and due diligence experiments and see to what extent the upgrades translated into improved performance on strategy analyses. In other words: is our AI Strategy Assistant ready to be promoted?
Exp: Consulting Case Interview. o1-preview outperformed GPT-4 on this experiment, replicating the performance of a top candidate in four out of five questions. The improvement came primarily from the upfront framing questions and reflects the difference between a “weak pass” to a “strong pass.” This result was largely expected given that the case interview questions rely heavily on sequential reasoning.
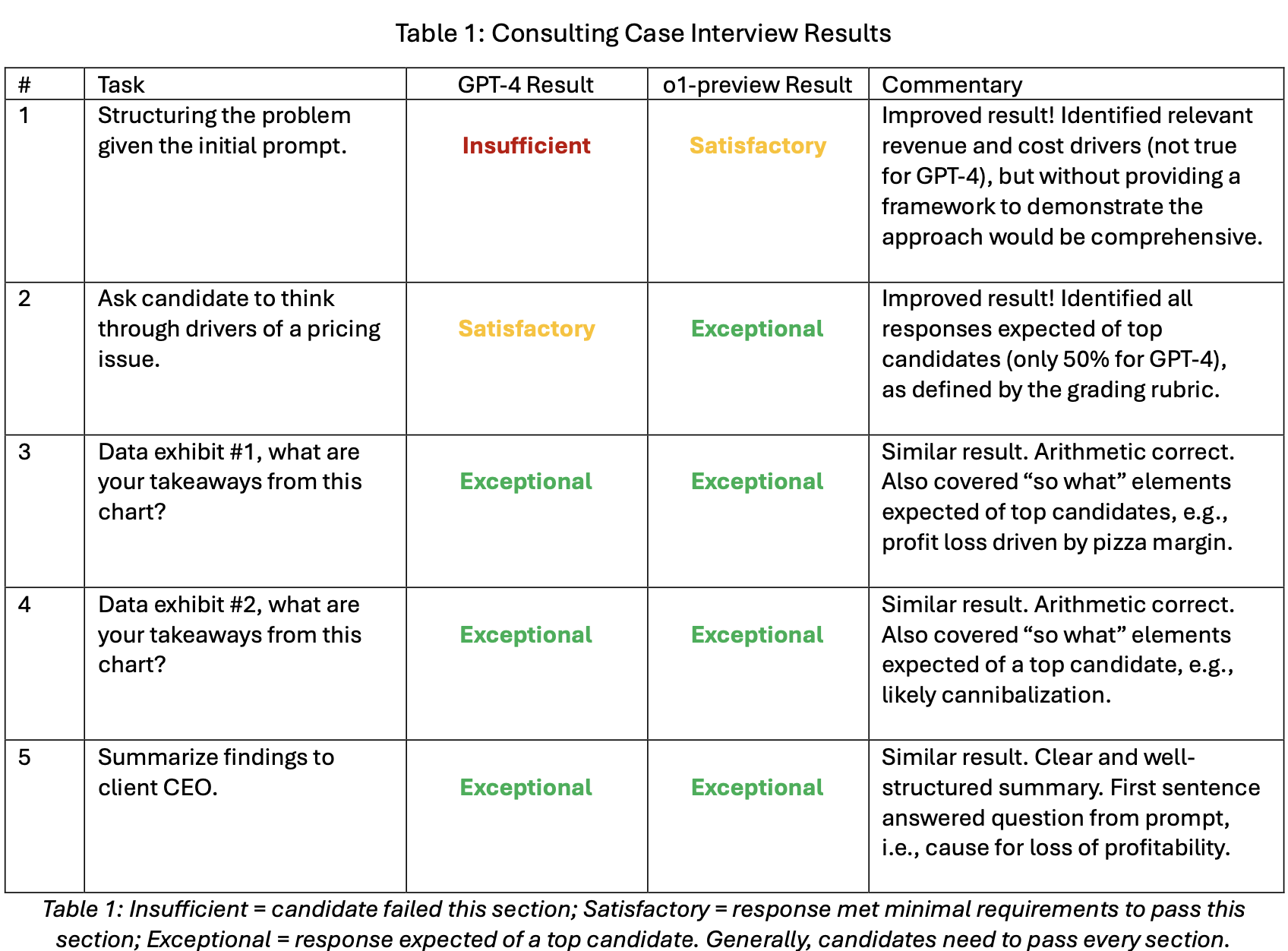
The only task for which o1-preview scored “satisfactory” (instead of “exceptional”) was the upfront problem framing. While this was already an improvement over the GPT-4 response (it identified hypothesis-driven set of revenue and cost drivers), it did not provide a unified framework to demonstrate that the proposed approach would be comprehensive.
Finally, as with GPT-4, the o1-preview model did not demonstrate the sorts of human behavioural qualities we expect of top candidates, despite pre-prompting. In particular, we want candidates to exhibit an inquisitive, curious mindset and “drive the interview” by proposing hypothesis-driven next steps to the interviewer. This is not necessarily a bug—we might prefer concise responses over extended thoughts on what to do next—just a limitation.
Exp: Buyside Due Diligence. o1-preview was substantially better than GPT-4 for the due diligence experiment, a result we did not expect. The experiment was designed intentionally to push the boundaries of this technology by combining complex multistep reasoning with large context window. In our original paper, as expected, we showed that GPT-4 largely failed this exercise—to the point where it was net unhelpful even as an assistant guided by a human.2 By contrast, o1 replicated the performance of a top candidate for three out of five tasks and would be an excellent assistant.

What surprised us most was how gracefully o1-preview handled complex contextual information, including tables for income statements, balance sheets, share information, synergy estimates, and a comparables analysis. The model’s results were not perfect (e.g., its depreciation and terminal value results were inaccurate), but these mistakes were minor and would have been common even among capable students doing this assignment. Moreover, the o1 models no longer hallucinate. The final task asks the LLM to recommend a share price that our buyer should be willing to pay, then resubmits the prompt to test whether the LLM might change its mind. GPT-4 offered two wildly different answers, but o1-preview offered the same response up to a rounding error. Although this does not eliminate the need of users to sense check the model’s results, it provides a more stable output that businesses can begin to build software checks and safeguards around.
One major caveat is that o1 models do not yet have access to the same user-friendly features that OpenAI has provisioned for GPT-4, such as file uploads, code execution, output schemas, and non-text modalities (e.g., image and video). This posed a potential problem for our due diligence experiment, since it inherently relied on contextual documents provided as file uploads. Fortunately, the context window size itself had not been limited (128,000 tokens, same as GPT-4 Turbo), and so we were able to work around the file upload constraint by running the code-based version of the experiment using OpenAI’s “chat completions” API and passing the context documents as “markdown text.” While this obviously limits the general usefulness of these models within a real-world business context (most business analysts and strategy consultants don’t code), we expect that OpenAI will add such functionality in the coming months. Therefore, our results really indicate the potential usefulness of these models for strategic management activities once such functionality is readily available through the user interface.
Conclusions. Remarkably, since our original paper (written April 2024, published September 2024), the ability of LLMs to handle strategic tasks involving multistep reasoning and context-dependence has improved significantly. There are two main conclusions we can draw from our study.
LLMs can already assist us for strategy tasks. Our updated experimental results indicate that OpenAI’s o1-preview model (without fine-tuning) would replicate the performance of a top candidate in a consulting case interview and produce a good useful draft effort of a buyside due diligence analysis. For us, this means LLMs can already begin to play a useful role as an assistant for strategy tasks, which was not true a few months ago.
Having a human-in-the-loop still matters. The due diligence experiment would not have been possible through pure automation. In particular, the model required repeated prompting to produce a complete answer, and without a human carefully sense checking the calculations, an analyst might have missed correcting different assumptions that the model was making.
Outlook: what does this mean? In the original article, we proposed that leadership teams need to decide “at what point should I start seriously investing?”2 The earlier you invest in developing significant software engineering around existing LLMs, you run the risk of building solutions that will become redundant over time, as performance natively increases with newer model versions (e.g., GPT-5, Claude-4). This is still the right question, but we are now more bullish about starting rather than waiting a few years for the technology to mature further. This is because the quality of the existing off-the-shelf models is already sufficient to be useful for many strategy tasks, and the software engineering you would need to put around it is orthogonal to the quality of the responses (which may further improve). For example, many of the systems we are building have significant input and output data-processing pipelines, but already minimal model fine-tuning. It would be the same here, for most strategic management applications.
The performance jump also points to a more uncomfortable question: will future updates remove the need to have humans in the loop for strategy tasks? We think this is still a long way off. The ability to anticipate the behaviour of other humans and make strategic decisions under uncertainty, which is fundamentally what investors do when they build a model of what a company may become and could do in the future, are not tested by our experiments but represent a big leap in complexity. That said, strategy consultants and investment analysts should certainly no longer be doing their work unassisted by these tools.
OpenAI. (2024). Learning to reason with LLMs. Simons Institute for the Theory of Computing. https://live-simons-institute.pantheon.berkeley.edu/talks/noam-brown-openai-2024-09-26
Lechner, C., Lang, N., Handschuh, S., Bouffault, O., & Cooper, J. (2024, September 12). Can GenAI do your next strategy task? Not yet. California Management Review.
OpenAI. (2024). OpenAI SDK (Version 1.2.3) [Software]. OpenAI. https://github.com/openai/openai-python






